Last Updated on September 17, 2025
AI Data Extraction Breakthrough for Receipts
Since early 2016 Tabscanner has been working tirelessly to solve the myriad and virtually endless formats of POS paper receipts. AI data extraction is a cutting edge technology with different approaches. Many OCR companies try to solve invoice data extraction through templates.
Whilst this can work quite well with consistent and structured formats; this approach is simply unscalable when creating a general global POS receipt OCR technology. More advanced methods are required when it comes to POS receipts. This is where Artificial Intelligence and Machine Learning come into play.
By early 2017 we had developed highly accurate and intelligent models that understood totals and subtotals. This was the foundation of our OCR technology. The advantages of AI in this area proved to be vastly superior to basic text parsing. This is when our technology really started to take off. Our accuracy rates on global POS receipt formats were over 92% and improving steadily with more data.
Line Item Data Extraction with AI machine learning

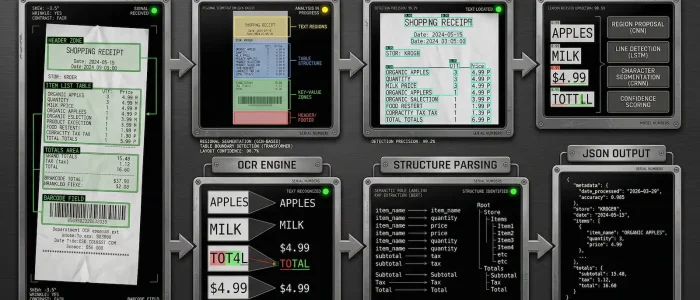
The next and biggest challenge we took on was the accurate identification of line item information on receipts. This was also a highly complex area as understanding where line items started and stopped was an extremely difficult task, sometimes even for humans.
We expanded our receipt testing platform (RTP) to around 5000 receipts and developed a guidance system for our AI to learn from. This was tested and refined on data that came into our technology from a highly successful global marketing campaign. Our Beta testers were sending receipts in from all over the world in a vast range of formats and languages.
One of the many early difficulties in solving this problem was that there was no clear identifiable patterns emerging on where retailers would place line items on receipts. Our machine learning algorithms had to become highly intelligent to solve this. Our RTP batch had clearly defined markers to identify the start and end of line items. So we were able to measure our success rates accurately as our technology improved.
AI Advanced Multi Language OCR

During this time we were making steady progress with our own proprietary AI OCR. We had begun using our OCR to train our models and were making advances in the clear understanding of line item data on our general technology.
By mid 2018 our RTP benchmark system had grown to over 40,000 receipts. It was now producing highly accurate identification rates above 80% on where line items started and ended.
Whilst this was very impressive and continually improving, supplementary lines were still a huge challenge in solving and extracting POS receipt line items. How stores organize their line item data, varies greatly and we needed to develop a very large set of specific tools to compliment what our AI had achieved in this area.
By the end of 2018 and assisted greatly by the volume of data from our early partners, we had reached line item data isolation levels of over 85% on our RTP batch.
The AI Breakthrough for Receipt Data Extraction
In 2019 our advanced multi language OCR and highly trained models made a breakthrough, achieving extremely accurate rates of AI receipt data extraction: over 95%. Combined with our own customization tools we are now reaching over 96% accuracy on many POC batches provided from partners all over the world.
“96% accuracy on line item receipt data extraction”
These rates are vastly superior to any other technology we have tested against. Our Tokyo data science team have achieved amazing results through the power of AI. With their own ingenious techniques and methods. They continue to hone and refine our technology daily. Ensuring Tabscanner continues to be the World’s most advanced receipt OCR technology.
Update Early 2025: The Tabcanner API recently had another breakthrough, pushing extraction accuracy rates even higher to 99%
Update mid September 2025: We can now offer 100% accuracy% accurate receipt data extraction.
The webinar below discusses this topic in more detail.

Based in Tokyo, Ben Smith is the Chief Technology Officer and Head of Research at Tabscanner. He pioneers deep learning models specifically designed for receipt optical character recognition (OCR) and document classification, engineering the core AI architectures that enable high-accuracy data extraction.